# mapreduce
[English](readme.md) | 简体中文
## 为什么需要 MapReduce
在实际的业务场景中我们常常需要从不同的 rpc 服务中获取相应属性来组装成复杂对象。
比如要查询商品详情:
1. 商品服务-查询商品属性
2. 库存服务-查询库存属性
3. 价格服务-查询价格属性
4. 营销服务-查询营销属性
如果是串行调用的话响应时间会随着 rpc 调用次数呈线性增长,所以我们要优化性能一般会将串行改并行。
简单的场景下使用 `WaitGroup` 也能够满足需求,但是如果我们需要对 rpc 调用返回的数据进行校验、数据加工转换、数据汇总呢?继续使用 `WaitGroup` 就有点力不从心了,go 的官方库中并没有这种工具(java 中提供了 CompleteFuture),我们依据 MapReduce 架构思想实现了进程内的数据批处理 MapReduce 并发工具类。
## 设计思路
我们尝试把自己代入到作者的角色梳理一下并发工具可能的业务场景:
1. 查询商品详情:支持并发调用多个服务来组合产品属性,支持调用错误可以立即结束。
2. 商品详情页自动推荐用户卡券:支持并发校验卡券,校验失败自动剔除,返回全部卡券。
以上实际都是在进行对输入数据进行处理最后输出清洗后的数据,针对数据处理有个非常经典的异步模式:生产者消费者模式。于是我们可以抽象一下数据批处理的生命周期,大致可以分为三个阶段:
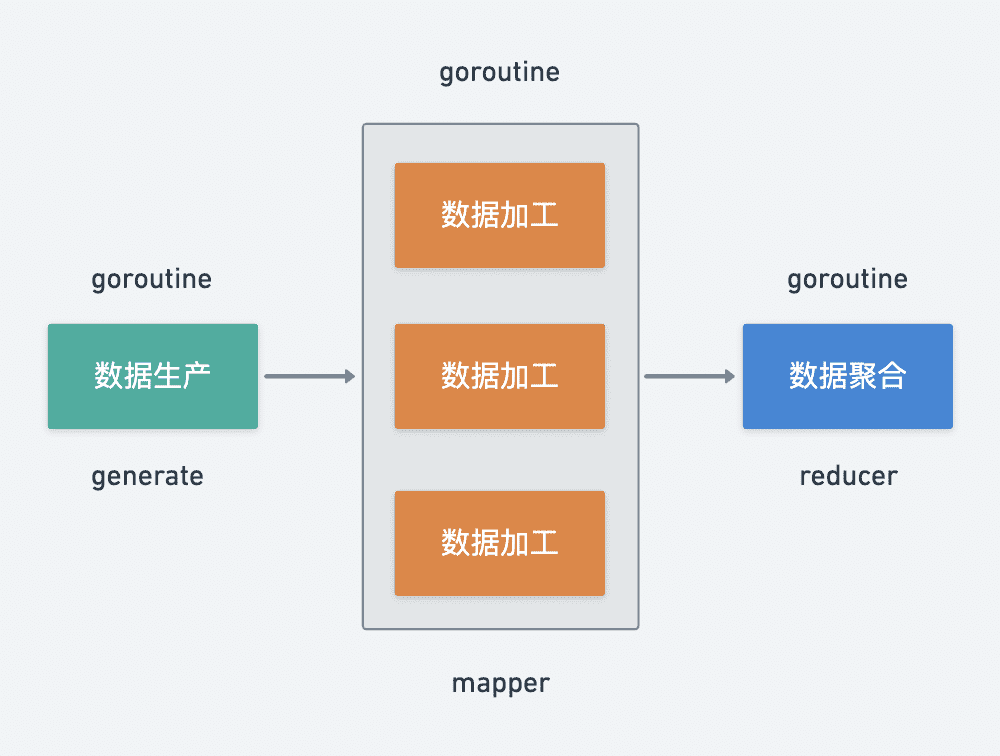
 1. 数据生产 generate
2. 数据加工 mapper
3. 数据聚合 reducer
其中数据生产是不可或缺的阶段,数据加工、数据聚合是可选阶段,数据生产与加工支持并发调用,数据聚合基本属于纯内存操作单协程即可。
再来思考一下不同阶段之间数据应该如何流转,既然不同阶段的数据处理都是由不同 goroutine 执行的,那么很自然的可以考虑采用 channel 来实现 goroutine 之间的通信。
1. 数据生产 generate
2. 数据加工 mapper
3. 数据聚合 reducer
其中数据生产是不可或缺的阶段,数据加工、数据聚合是可选阶段,数据生产与加工支持并发调用,数据聚合基本属于纯内存操作单协程即可。
再来思考一下不同阶段之间数据应该如何流转,既然不同阶段的数据处理都是由不同 goroutine 执行的,那么很自然的可以考虑采用 channel 来实现 goroutine 之间的通信。
 如何实现随时终止流程呢?
`goroutine` 中监听一个全局的结束 `channel` 和调用方提供的 `ctx` 就行。
## 简单示例
并行求平方和(不要嫌弃示例简单,只是模拟并发)
```go
package main
import (
"fmt"
"log"
"github.com/zeromicro/go-zero/core/mr"
)
func main() {
val, err := mr.MapReduce(func(source chan<- interface{}) {
// generator
for i := 0; i < 10; i++ {
source <- i
}
}, func(item interface{}, writer mr.Writer, cancel func(error)) {
// mapper
i := item.(int)
writer.Write(i * i)
}, func(pipe <-chan interface{}, writer mr.Writer, cancel func(error)) {
// reducer
var sum int
for i := range pipe {
sum += i.(int)
}
writer.Write(sum)
})
if err != nil {
log.Fatal(err)
}
fmt.Println("result:", val)
}
```
更多示例:[https://github.com/zeromicro/zero-examples/tree/main/mapreduce](https://github.com/zeromicro/zero-examples/tree/main/mapreduce)
## 欢迎 star!⭐
如果你正在使用或者觉得这个项目对你有帮助,请 **star** 支持,感谢!
如何实现随时终止流程呢?
`goroutine` 中监听一个全局的结束 `channel` 和调用方提供的 `ctx` 就行。
## 简单示例
并行求平方和(不要嫌弃示例简单,只是模拟并发)
```go
package main
import (
"fmt"
"log"
"github.com/zeromicro/go-zero/core/mr"
)
func main() {
val, err := mr.MapReduce(func(source chan<- interface{}) {
// generator
for i := 0; i < 10; i++ {
source <- i
}
}, func(item interface{}, writer mr.Writer, cancel func(error)) {
// mapper
i := item.(int)
writer.Write(i * i)
}, func(pipe <-chan interface{}, writer mr.Writer, cancel func(error)) {
// reducer
var sum int
for i := range pipe {
sum += i.(int)
}
writer.Write(sum)
})
if err != nil {
log.Fatal(err)
}
fmt.Println("result:", val)
}
```
更多示例:[https://github.com/zeromicro/zero-examples/tree/main/mapreduce](https://github.com/zeromicro/zero-examples/tree/main/mapreduce)
## 欢迎 star!⭐
如果你正在使用或者觉得这个项目对你有帮助,请 **star** 支持,感谢!